引言
为了获得准确的定量结果,最好尽量减少通过物理模型对原始测量数据进行校正。原始测量强度校正得越少,模型和基本参数的不确定性对最终定量结果的影响就越小。减少校正需求的方法之一是检测标样或使用已检测的标样库。EDAX为eZAF开发了全标样定量(FSQ)。
但是这也导致分析人员承担更多责任,需要合理地选择标样并仔细地进行检测过程。必须要指出的是,至少在经典方法中,标样需要在实验室现场具有可靠的已认证的成分(即使是微米级的均匀性)。而使用EDS过程中,其提供的是使用之前测量的标样库甚至是一个集中数据源[1]。
结果与讨论
首要的问题终归是应该使用哪一种可用的标样来评估未知的样品谱。FSQ呈现了与实际检测标样值相关的k-比值(检测的未知谱计数除以标样计数)。这与EDAX早期基于标样的定量算法不同,在早期,k-比值总是与纯元素标样相关(如果没有纯元素标样可供检测,则计算纯元素标样)。这就明确了实际应用是有校正的。此外,所有的误差计算是基于应用修正的。如果不需要校正或校正极小,那么实际上该模型不会产生系统误差的影响。
图1演示了标样的选择将如何影响最终的校正需求。在示例1b中,由于标样更接近未知样品Fe的成分,Fe的Z校正被降低了。然而最终目标是使用磁铁矿标样(1c)实现的,其中eZAF模型所需的修正最终低于2%。在理论上,这意味着需要原始数据来校正检测标样与未知样品数据之间约2%的差异。这个示例的有趣之处在于,即使是最小校正需求的标样也与最佳测量的k-比值不同。
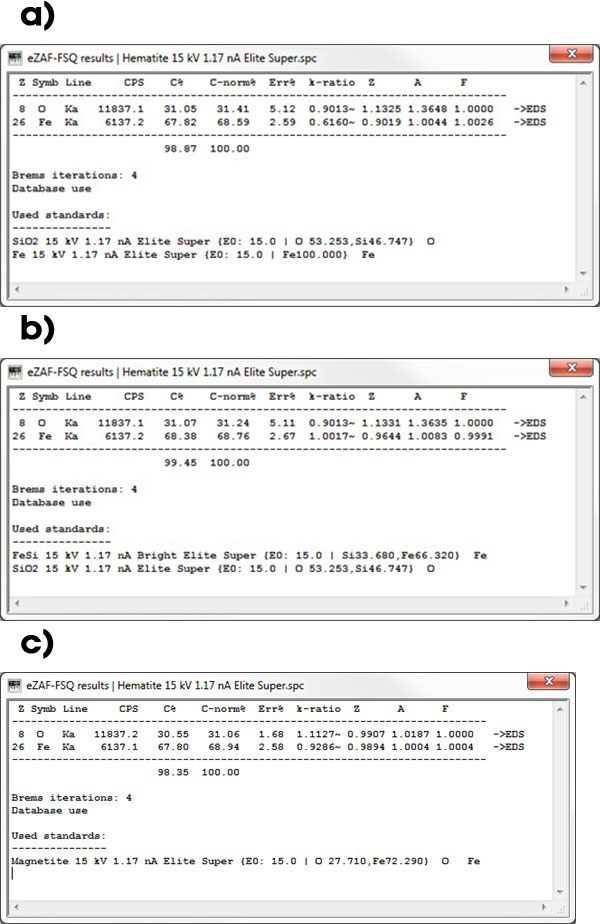
图1. a) 赤铁矿样品的FSQ评估,基于以检测标样SiO2做为O的标样强度以及检测纯Fe标样做为Fe的标样强度。b) 样品相同但以FeSi化合物做为Fe检测的标样。c) 样品相同使用磁铁矿做为两元素的标样,与a和b相比,成分构成上更加接近。
与纯元素标样的eZAF结果相比,其好处是显而易见的(图2)。虽然Fe-K修正所需的量不大,但氧R和A修正量很大,在无标样的情况下理论吸收修正量可达近60%。这种情况在所有依据标样支持的检测条件下是很少有的。当使用SiO2标样时,修正量降低,只有36%左右,尽管其成分仍然与未知样品相差很大。
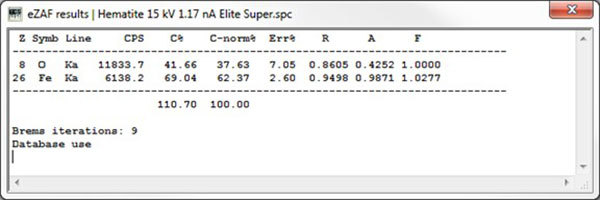
图2. 赤铁矿样品eZAF无标样评估
T使用标样(用自己的仪器测量)的好处是,它消除了探测器效率的不确定性(EDAX Insight 2021年9月号)。这尤其影响了示例中的氧的结果。比如,Fe无标样非归一的结果已经很不错,但是氧仍然被高估了。
然而,我们可以看到,选择使用哪种标样是由操作者决定的。新的EDAX软件支持这一点,它通过应用ZAF因子来呈现施用的校正需求,ZAF因子很大程度上依赖使用标样的成分。此外,误差%值包括系统误差的评估。例如,氧的无标样评估误差在7%以上。即使采用不理想的标样,它也改善到5%左右。最后,据报道,使用磁铁矿标样,氧的误差为1.6%。因此,可以在软件的支持下对标样的选择进行优化。但是如果没有先前的经验,它可能会变成试错的工作。智能应用软件基于对未知样品无标准结果的预期,可以支持您最佳的标样猜测。而eZAF-FSQ基础算法仍然需要对必须提供的标样数据进行预选。
难道不应该为算法提供所有相关可用的和测量的标样,然后自动选择尽可能少的修正需求的最佳匹配标样吗?SmartStandards能够访问所有提供的标样数据,该算法优化了在迭代过程中应考虑评估的标样[2](图3和4)。
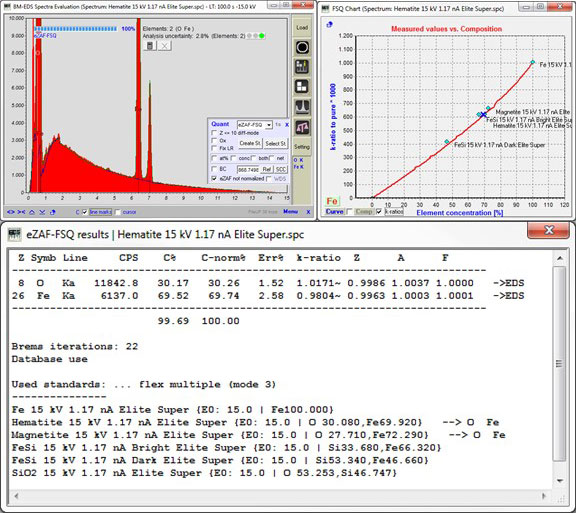
图3. 使用SmartStandards进行赤铁矿评估,选择需要最少校正的最接近的标样。Err%几乎只是测量的统计波动(未知样品和标样),几乎没有系统误差部分。曲线显示了通过具有k-比值(相对于纯元素)的Fe标样(菱形)与Fe浓度调整的eZAF模型。
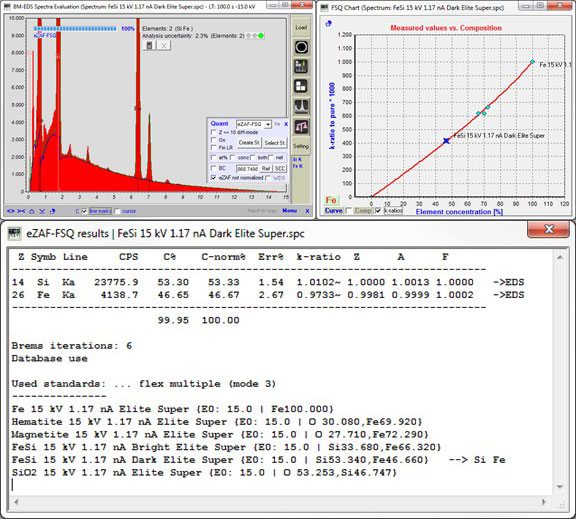
图4. 使用相同的标样数据,用SmartStandards评估FeSi样品谱。再次证明,由算法迭代过程自动选择的标样是最接近的。修正因子和Err%接近理想状态。曲线显示了使用通过具有k-比值(相对于纯元素)的Fe标样(菱形)与Fe浓度调整的eZAF模型。
在理想情况下,利用Al/Si标样链的重复参考实例对曲线进行改进。在整个浓度范围内,相对偏差可小于2%(图5)。
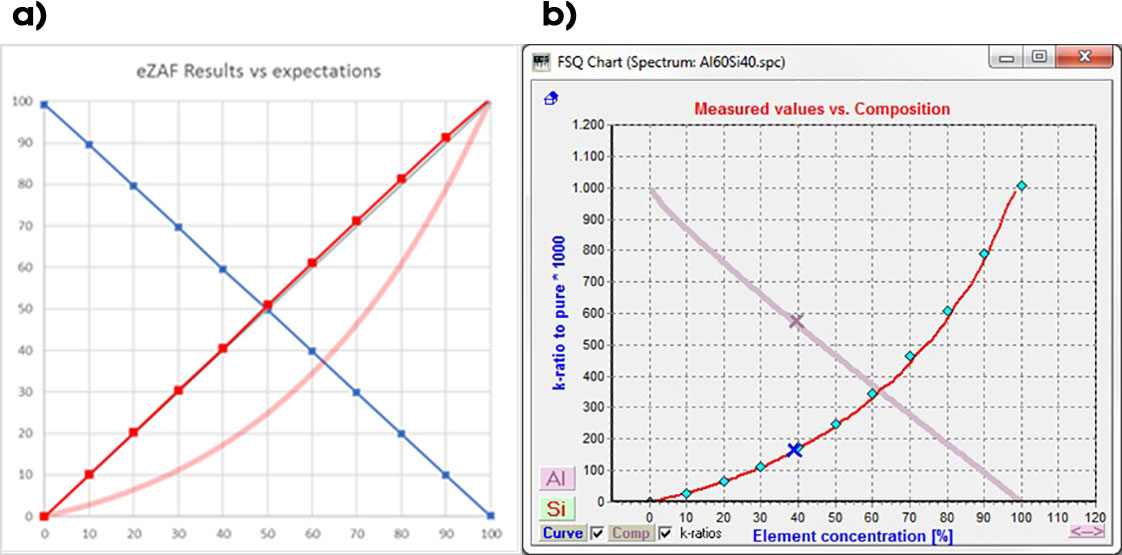
图5. a) 用SmartStandards对二元Al/Si示例样品(蓝色为Al;红色为Si)计算浓度结果除以Si的名义浓度,所有单位为%,对于Al中的Si-K使用MACC。宽的浅红色线是Si净计数原始数据曲线,任意单位,尚未进行ZAF修正。b) 净计数与所有使用标样(菱形)浓度的FSQ绘图;通过标样调整计算出eZAF曲线,并对平滑变化的基体成分(红色为Al;暗红色为取逆向X轴为100%-CAl%的Si)进行评估。符号是对40% Si/60% Al样品谱评估的测量点。
对于在用户仪器上检测标样的一种并行和可选的方法是创建一个不断增长的全球标样库,其中包括使用其它地方检测的标样测量数据[1]。这个通用的标样库可以继承客户基于SmartStandards的本地检测结果。至少,必须应用一个参考测量,这将在其它检测标样和用户仪器操作之间建立起桥梁。参考测量值是来自eZAF无标样、未归一化的已知量(EDAX Insight 2021年9月号)。
如果使用了SmartStandards,提供了尽可能多的标样,这些标样可以非常紧密地覆盖整个浓度范围(例如,理想状态是100个标样可以据有1%的步长来紧密覆盖所有浓度),那么eZAF模型就非常智能了。然后,它只处理剩余的微小偏差(例如,在31%和32%的元素标样之间,如果未知量是31.3%)。可以想象,所提供的标样链是由蒙特卡罗模型(Monte Carlo, MC)计算支持的,甚至仅由蒙特卡罗计算提供的;这是完全取代ZAF或Φ(ρz)模型的第一步,使用一个大型的、自动关联的标样数据库,该数据库可用于持续访问,或者MC总是提前计算出给定的组合。纯元素样品基准检测可以作为不同系统测量的标样与MC计算模型之间的桥梁。但这需要探测器效率可,或者,可以使用简单的本地检测的标样桥接到更大的中央标样库。一个愿景是,大型的远程标样库能够包含更接近于在SEM中本地检测未知样本的标样,而不是自己的简单标样[1]:如果可以对每个元素进行本地标样检测,那么就可以抵消检测器效率的不确定度。
参考文献
[1] Ritchie N et al. (2020) “Let’s Develop a Community Consensus K-ratio Database” Microscopy and Microanalysis 26 Suppl 2 (2020) 1774
[2] Eggert F (2021) “Abilities Towards Improved Accuracy in EPMA” Microscopy and Microanalysis 27 Suppl 1 (2021) 2021